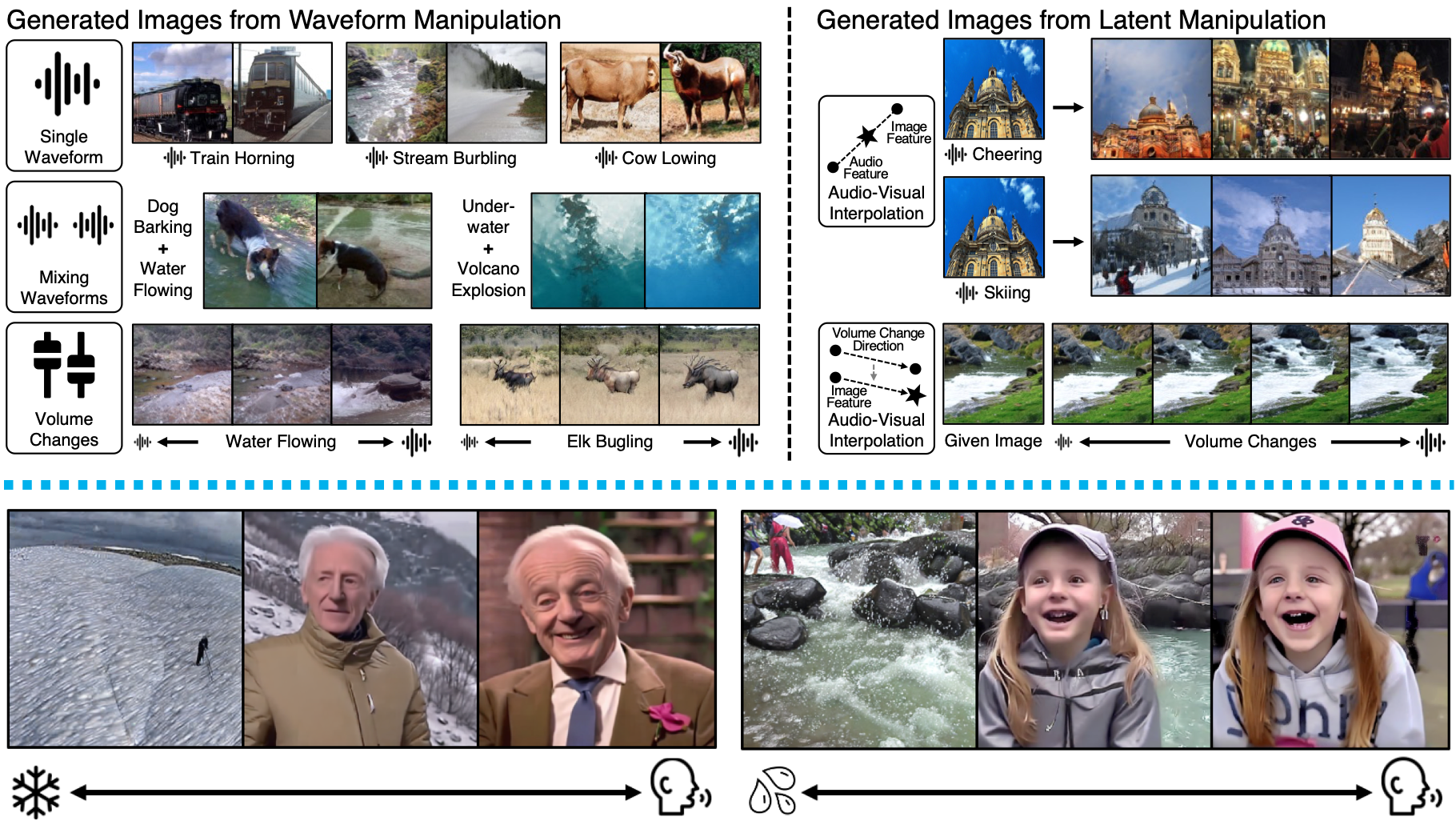
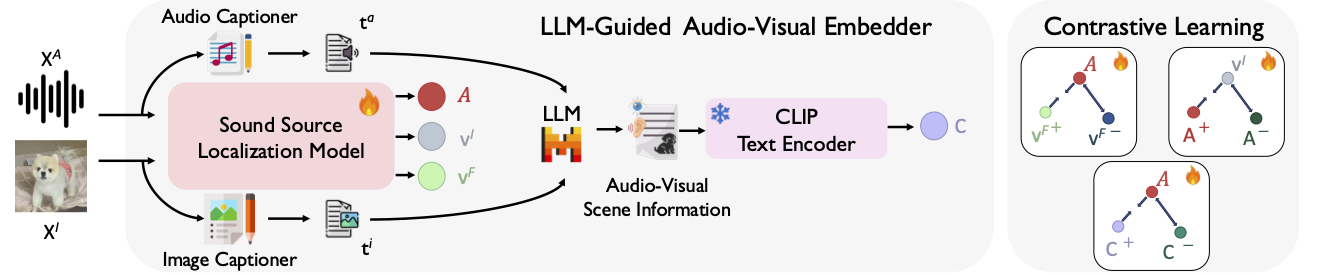
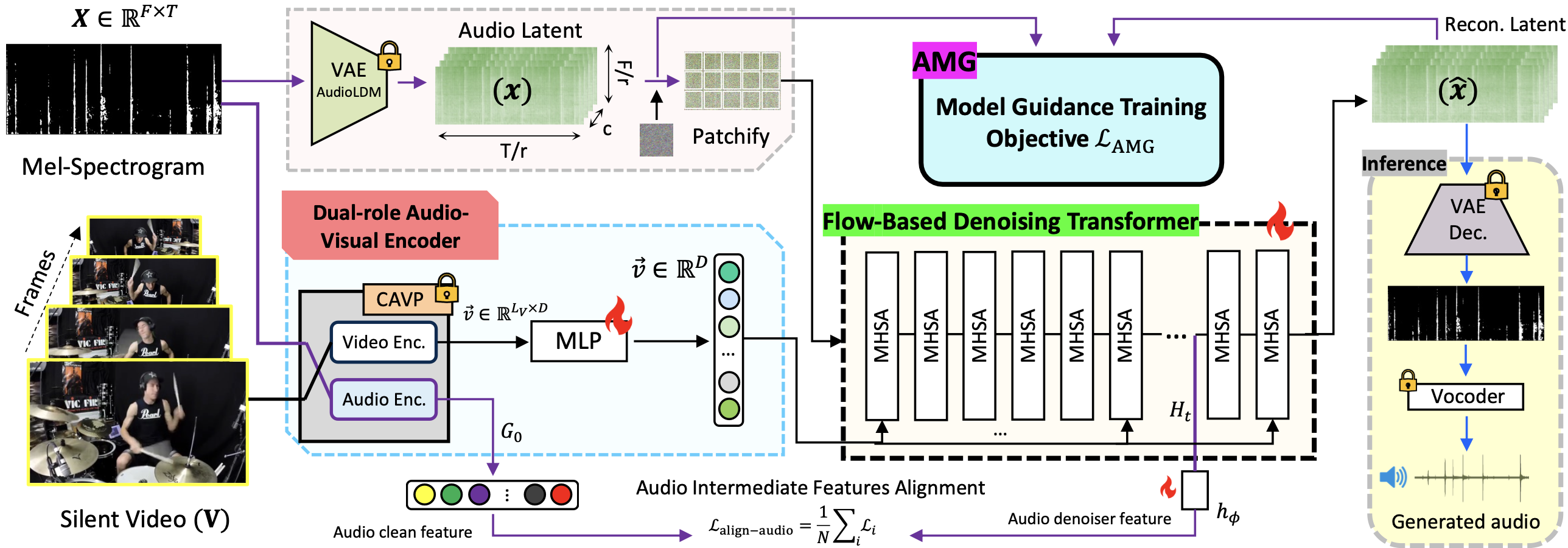
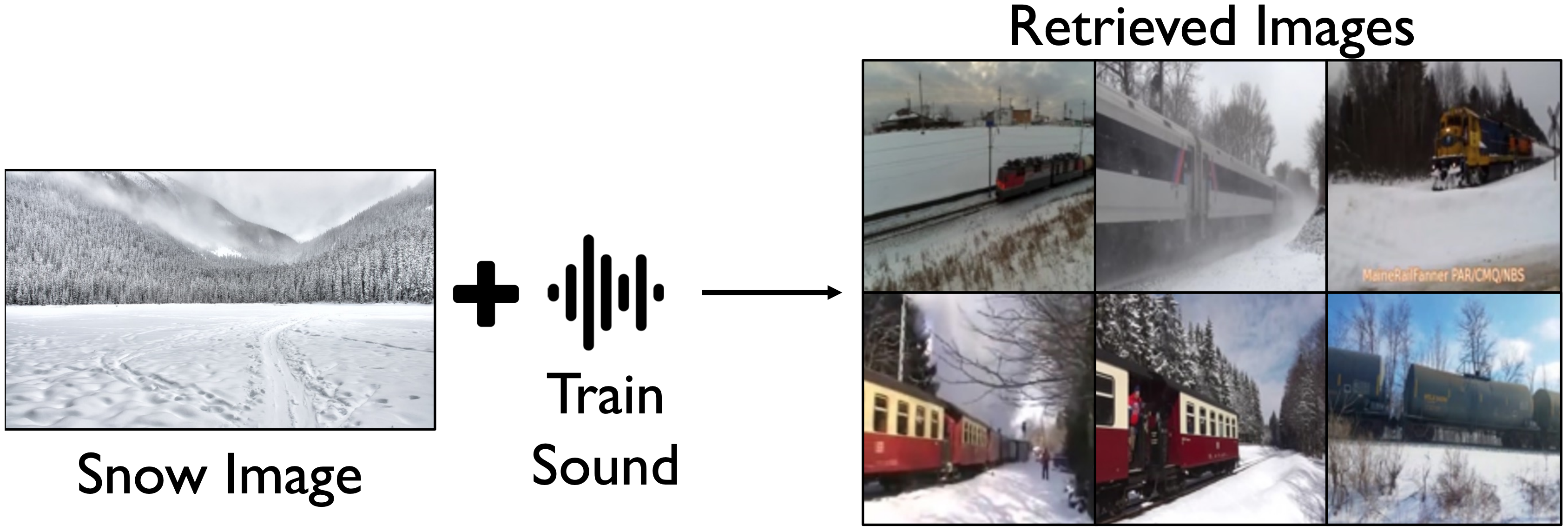
- October 2025: Selected as an Outstanding Reviewer at ICCV 2025.
- September 2025: One paper is accepted to NeurIPS 2025.
- September 2025: One paper is accepted to IJCV 2025.
- September 2025: I joined UNIST as an Assistant Professor 🧙♂️
- May 2025: One paper is accepted to TPAMI 2025.
- February 2025: One paper is accepted to CVPR 2025.
- January 2025: One paper is accepted to ICLR 2025.
- October 2024: AudioMamba is accepted at SPL (Signal Processing Letters)!
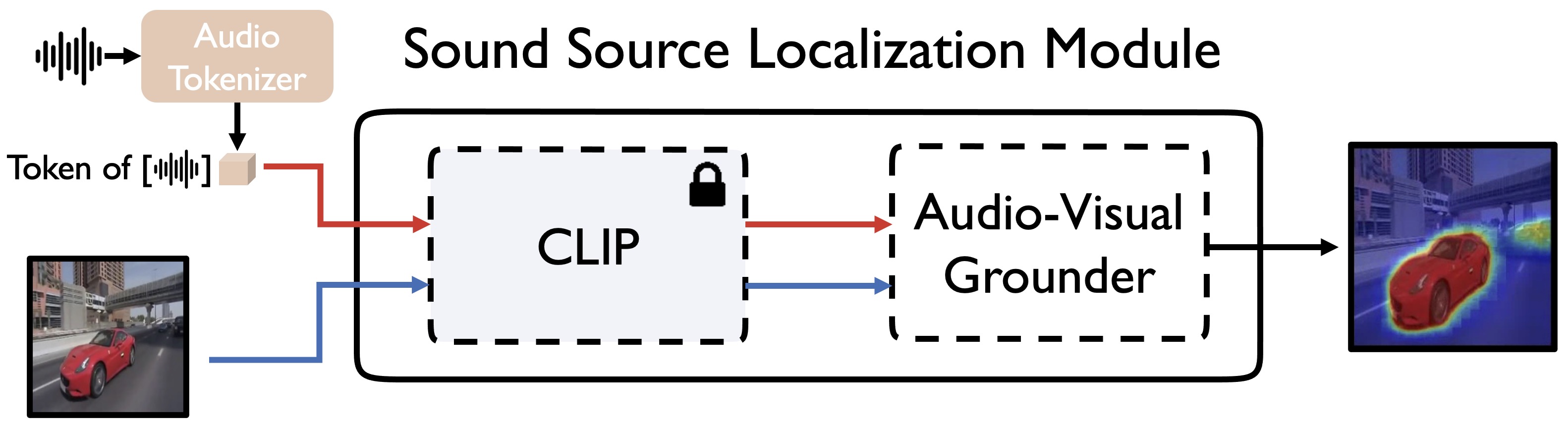
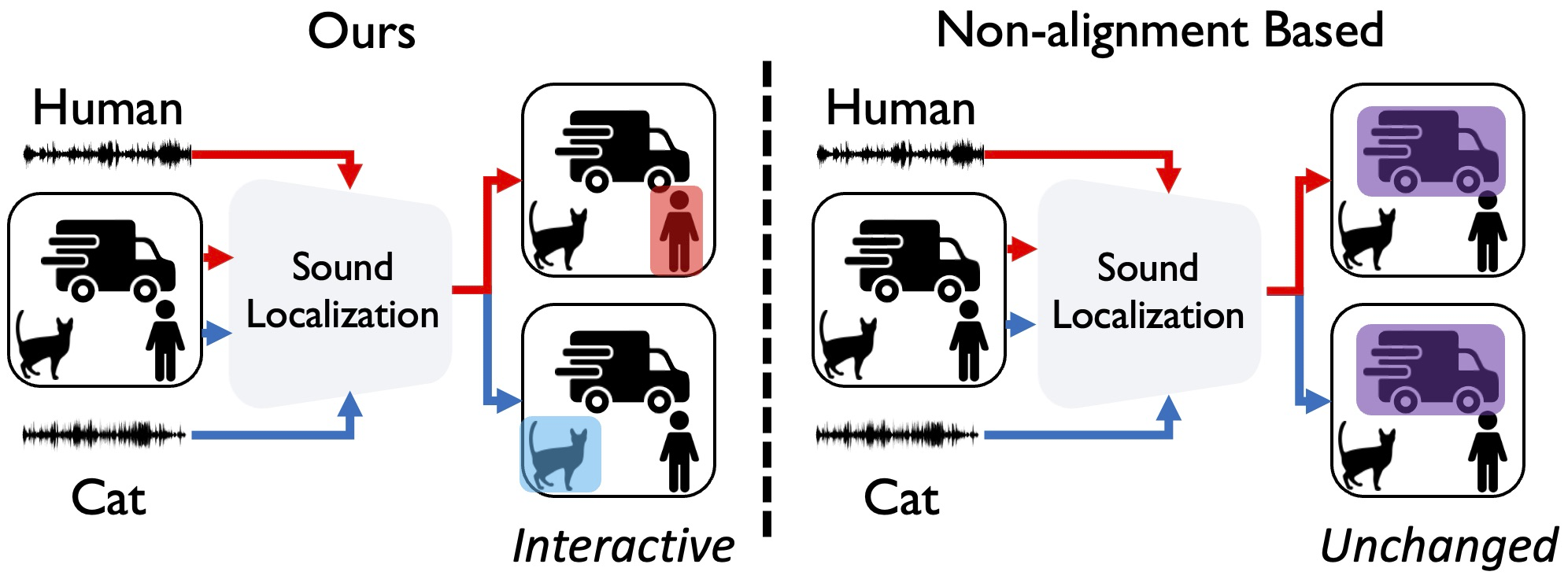
- July 2024: A new extensive Sound Source Localization Analysis is released!
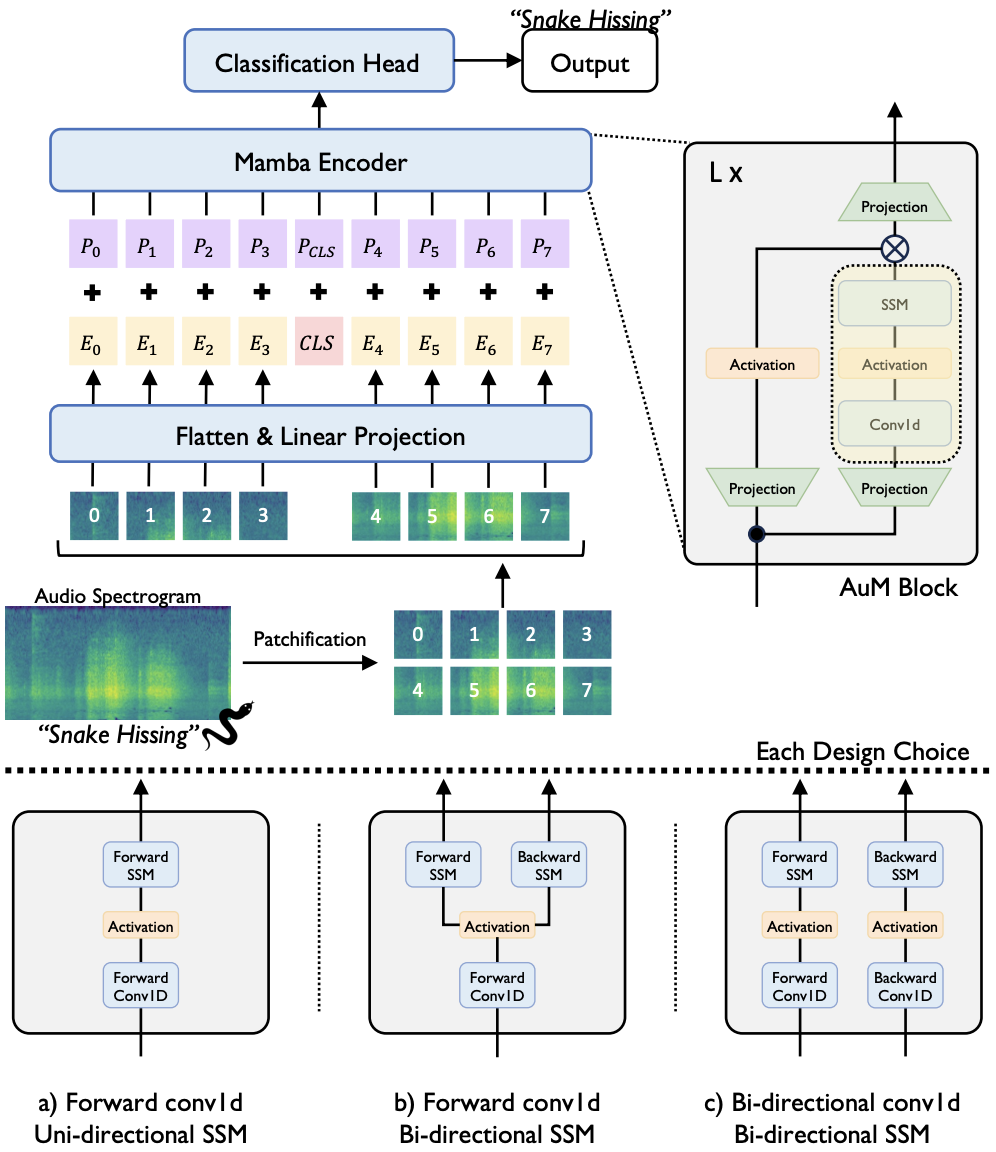
- June 2024: AudioMamba is released!
- June 2024: One paper is accepted to INTERSPEECH 2024.
- December 2023: Two papers are accepted to ICASSP 2024.
- October 2023: One paper is accepted to WACV 2024.
- October 2023: Selected as an Outstanding Reviewer at ICCV 2023.
- July 2023: One paper is accepted to ICCV 2023.
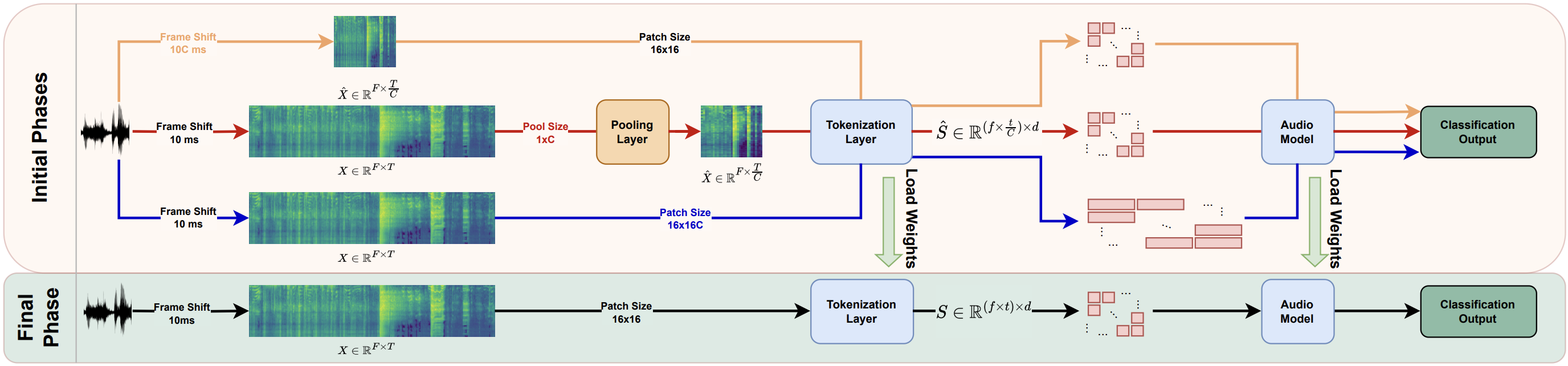
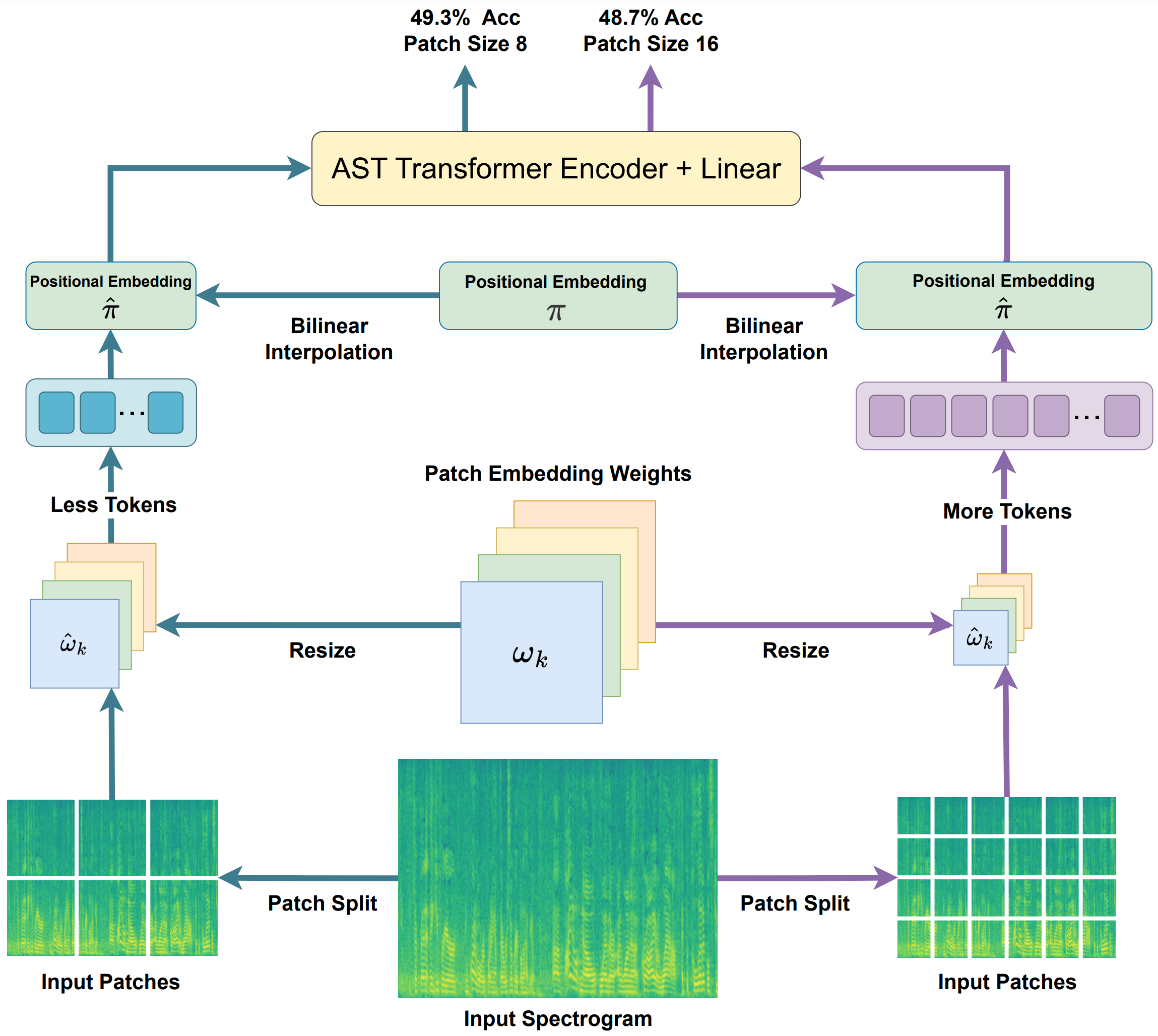
- May 2023: FlexiAST is accepted to INTERSPEECH 2023.
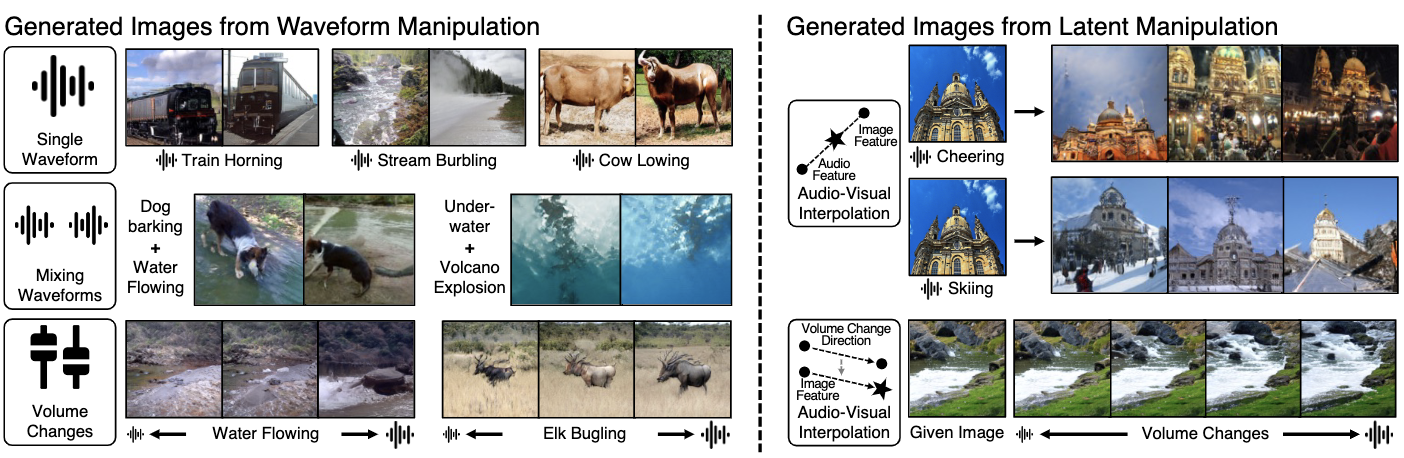
- Jan 2023: Sound2Scene is accepted to CVPR 2023.

Arda Senocak
I am an Assistant Professor in the Graduate School of Artificial Intelligence and the Department of Computer Science and Engineering at UNIST.
Prior to that, I spent three wonderful years at the Multimodal AI Lab at KAIST. From 2022 to 2025, I was a Postdoctoral Researcher in the School of Electrical Engineering at KAIST, working with Joon Son Chung. I later worked as a Research Assistant Professor in the same department.
I completed my Ph.D. and M.S. at KAIST EE (advised by In So Kweon), and also received my B.S. degree from KAIST CS.
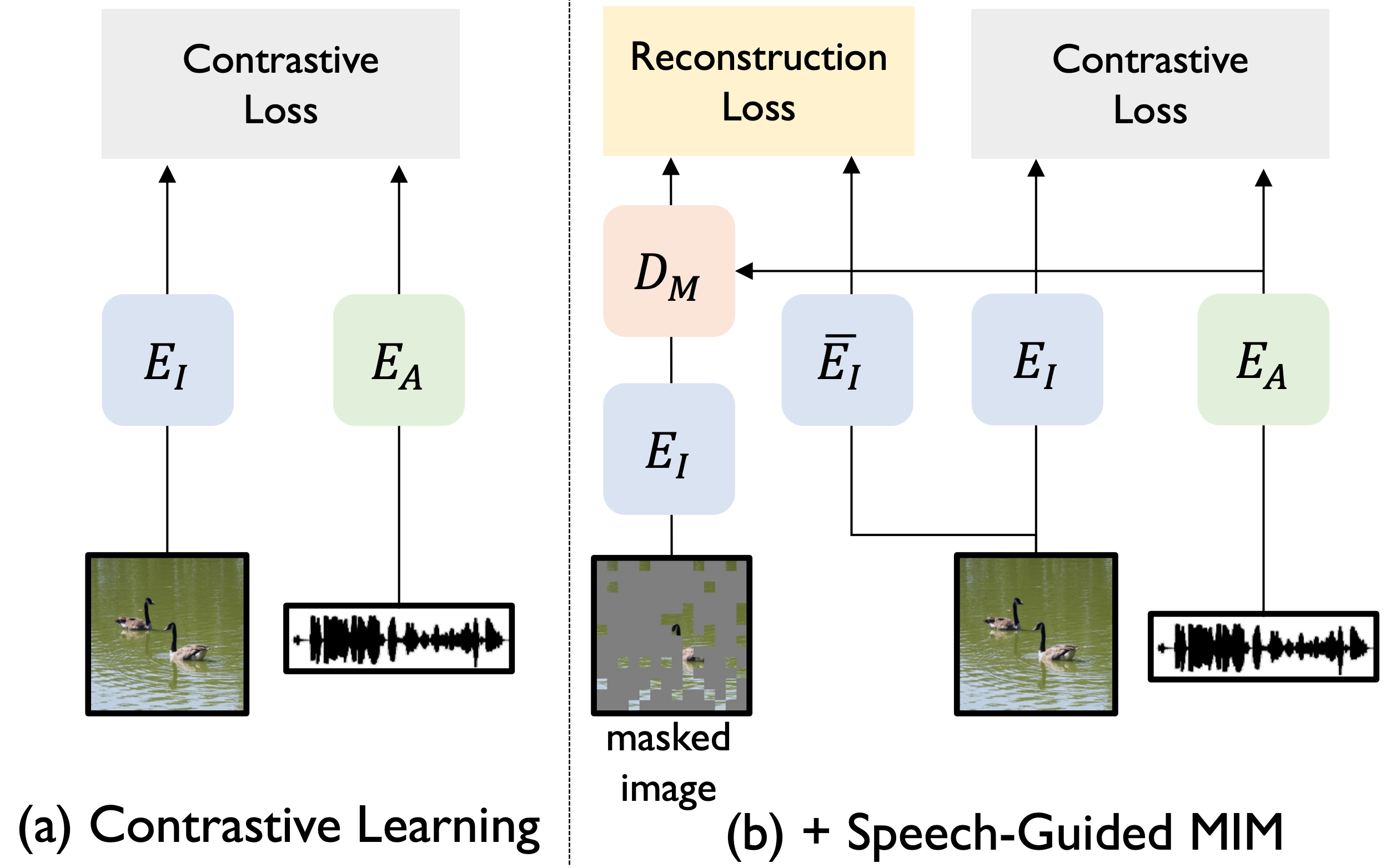
My research focuses on multimodal learning, particularly on developing machine perception models that can learn from visual, auditory, and other sensory inputs to effectively interact with the world around them.